


Summary
Are you making the most of your computing power? Traditional provisioning of computing resources is inflexible and has to handle peak demands meaning that a large chunk of the time it could be sitting idle, but you still pay for it. On-demand and serverless cloud computing allow customers to minimise unnecessary costs and provide better return on investment. This kind of computing relies on elastically scaling up and down computing resources depending on demand.
Cloud Computing Can Be Costly
Cloud computing was the future a few years back and it is basically mainstream now. Software-as-service offerings in the cloud are proliferating as well. Hence, businesses are paying more and more for cloud services as a proportion of their running costs. In a recent research published by the VC fund Andereesen Horowitz (US), the authors estimate that “cloud spend ranging from 75 to 80% of cost of revenue was common among software companies”, which begs the question if such a high proportion of the cost of revenue is reasonable. Their findings suggest that for any IT company there are now two big cost centres – employees and cloud computing. Conversely, a large chunk of investors’ money pays for cloud computing nowadays.
Is there a better way?
Have you heard the joke about the junior developer who forgot to switch off the GPU cloud instances over the weekend? Probably not, because nobody was laughing that day. I certainly didn’t laugh when I forgot to switch off a RedShift instance and got the bill. Well, it happens to all of us, but such mistakes can be rather costly for a big organisation.
Traditionally provisioning of cloud resources is an educated guess and often a fixed one in time. Typically, a team would make sure that peak loads can be handled by the system, i.e. no matter what you throw at it, the system will cope at the cost of being underutilised the rest of the time. But, how often do you see these peak loads, once a day, week or month? Can you predict them somehow?
In an ideal world, based on historical data and some heuristics it should be possible to write an algorithm that can anticipate peaks and troughs in the demand and provision resources accordingly. In practice this is rather difficult to achieve. However, serverless or on-demand computing comes close enough.
On-demand and serverless cloud computing to the rescue
On-demand computing is a catch-all term but it is in general understood as paying only for what you use, like storage, RAM, CPUs/GPUs, network traffic. For instance, Google BigQuery is a managed SQL-like database which charges customers based on the amount of data it stores.
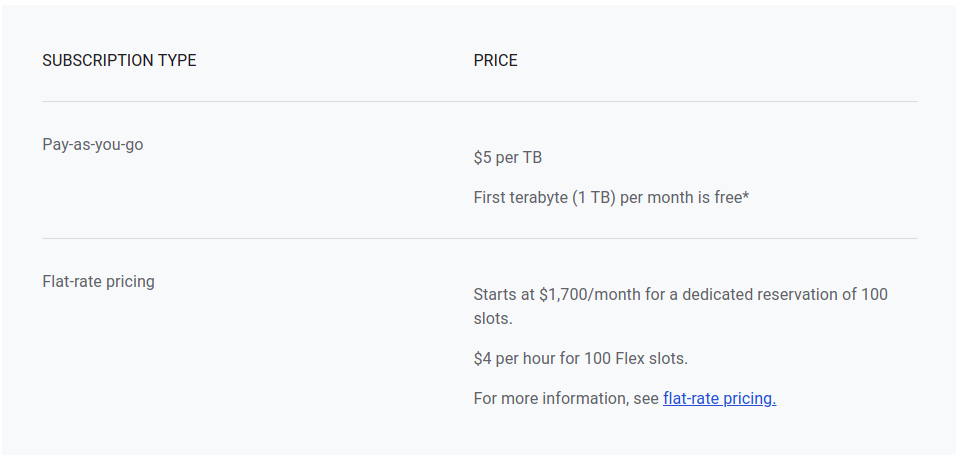
BigQuery subscription pricing (as of 14.01.2022)
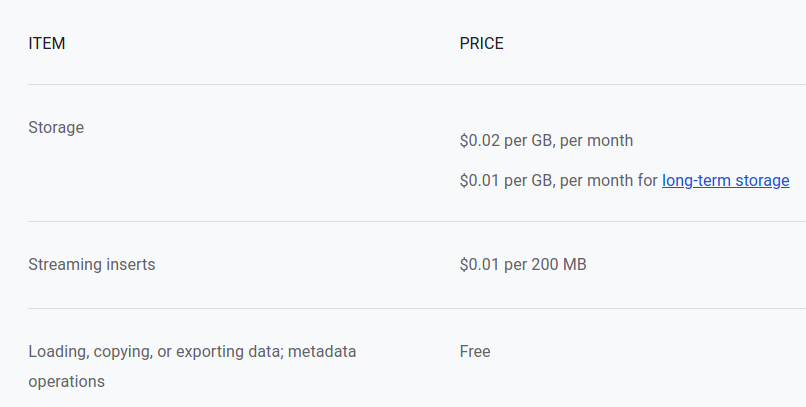
BigQuery storage pricing (as of 14.01.2022)
This approach is advantageous if you don’t have a large amount of data or just want to make a prototype. The old way would be to commit to 50 TB but effectively use only 10 TB. The ability to pay dynamically for every extra byte is a great improvement; it offers an easy way of estimating costs and makes trade-offs more transparent. Here is a link to a calculator comparing AWS Lambda (serverless) service vs. AWS SageMaker in the context of training machine learning models with Python. For an API serving up to 2,000,000 requests per month on average 600 ms long, AWS Lambda remains way more cost effective than SageMaker.
What is serverless cloud computing then?
Serverless cloud computing is a paradigm where customers pay on-demand for resources like compute (CPU) time, RAM and storage together. It is a way of abstracting the infrastructure provisioning and letting the cloud provider decide on the best way to distribute the virtual machines inside their data centre.
For example, running a simple service on Google Cloud Run costs $0.00002400 per CPU-second (as of 17.01.20222). Calling the service for 10 min every day for a month adds up to approximately $0.5! Such billing structure is ideal for low and medium loads where the functionality is needed intermittently. 10 minutes per day are more than enough to run a simple data transformation on a dataset.
Below are three estimates for the monthly cost for running Cloud Run in the London data centre. For simplicity it was assumed that each request is processed by exactly one instance of the code. This is a simplification, because more often than not one instance can handle more than requests at a time reducing the costs further. Nevertheless, the data shows how building a serverless API in the cloud with quick response times can be really cost effective. When the response times increase, the prices go up quickly and become comparable to simply running a large server instance continuously.
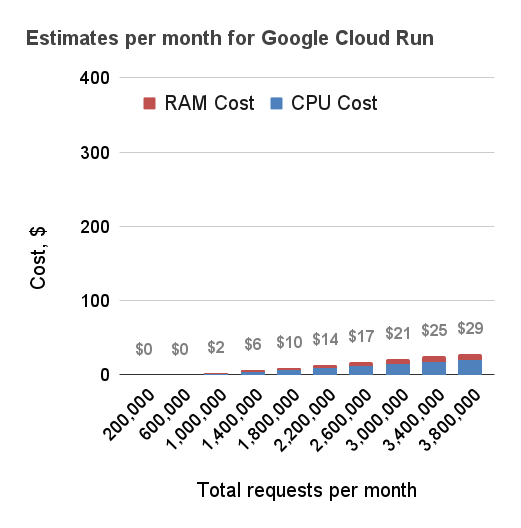
100 ms per request
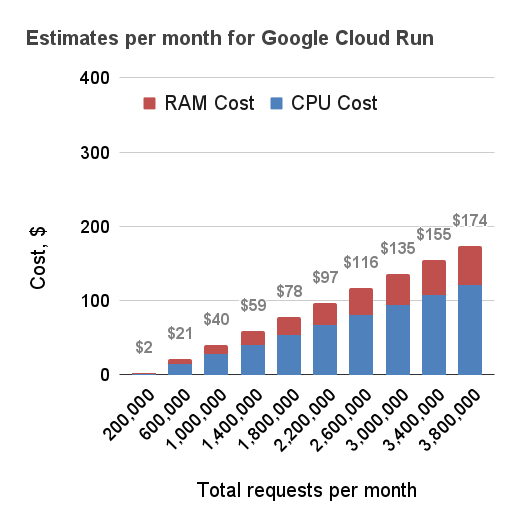
500 ms per request
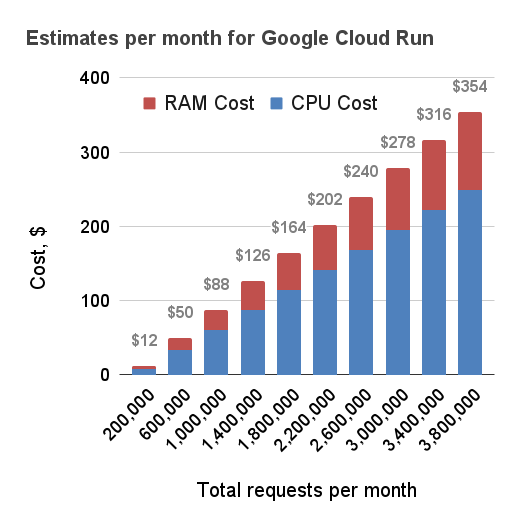
1000 ms per request
This chart shows how billable time is estimated when one instance of Cloud Run responds to multiple requests at a time:
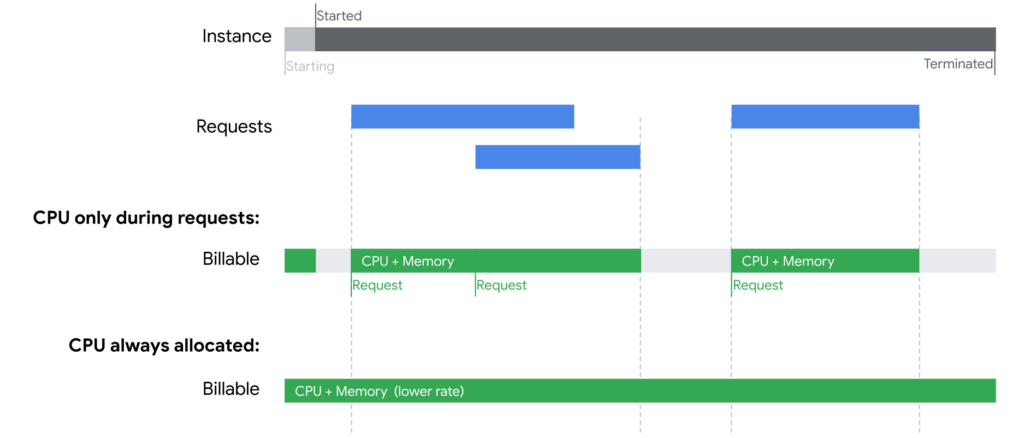
Source: https://cloud.google.com/run/pricing (20.05.2022)
In conclusion, with serverless there two main strategies to minimise costs:
- Run virtual machines to only when needed
- Optimise the code to process multiple requests on the same instance (when possible)
Are there any problems with serverless architecture?
Not everything is meant to be run using serverless / on-demand mode. For instance, traditional SQL databases are not built for such deployment yet. There you would still end up paying for a cloud server to run continuously for the sake of the DB regardless of the utilisation.
The main issue with serverless architecture is that it can be slower to respond. Every time a request is sent to the system it has to first spin up an instance to run your code, before it can respond. Simply put, a virtual machine has to be provisioned in the data centre with its own CPU, RAM and storage (and a lot more). This is called a cold start. These days, vendors have ways of getting around it by offering you to run a handful of instances in the cloud just in case a request comes in. This solution of course raises the costs because now your code is running 24/7. That approach is still acceptable because serverless instances have only a handful of CPUs each compared to a full-blown server with 36 of them for example. Practically setting any contingency buffers to zero is not possible, but with serverless you can keep such costs to a minimum.
An example
The diagram shows a simple example of a cloud system which runs an extract-transform-load process on Google Cloud. Cloud Scheduler can be configured to call a Cloud Run service regularly, let’s say once a day. Cloud Run spins up a cloud instance (virtual machine) every time which runs some custom code for fetching Facebook user interactions for example from Facebook’s system. The code would also process the data and finally push it to a SQL database.
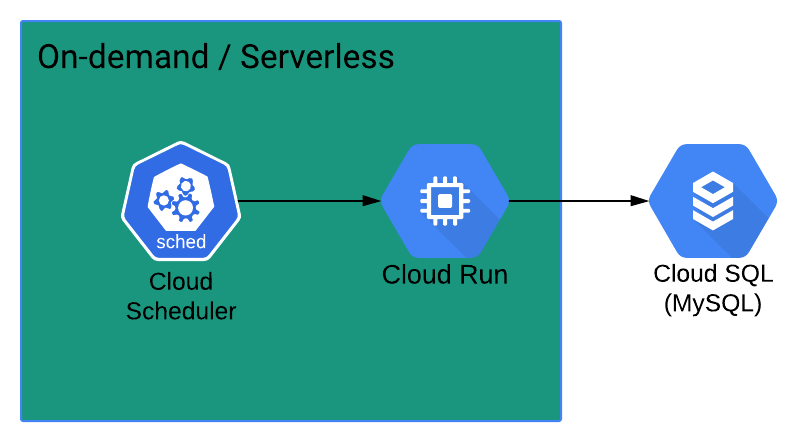
In the past this solution would have required an instance running all the time and the associated costs. Nowadays, only the database needs to be on all the time and even that could be replaced with a pay-as-you-go option if necessary.
Note! Designing a system for serverless deployment gives you more flexibility than creating a monolithic application. A system that can run as independent microservices can always be packages to run as a monolith on a single virtual machine with lots of CPUs. The way around is not possible without substantial changes to the architecture. Starting with a serverless mindset using microservices guarantees that you can always the best possible price regardless of your scale.
Conclusion
Why make it simple when you can make it complicated! / Pourquoi faire simple quand on peut faire compliquer!
At Techccino we believe in simplicity because it reduces costs. In that sense, on-demand and serverless cloud computing are definite winners in terms of reducing costs and efficiency. The simplicity comes from off-loading the infrastructure provisioning to the cloud vendor and the business can focus on the business logic and serving customers.
References
- For a technical overview of serverless read the intro by Mike Roberts @ www.martinfowler.com here.
- Spark on Knative (true serverless) by Rachit Arora
- Scale-Out Using Spark in Serverless Herd Mode! by Opher Dubrovsky and Ilai Malka
- What Makes Serverless Difficult And How Thundra Can Help by Suna Tarıyan